|
 All ingested data files are referenced in a dedicated collection. Datasets contained in products are located in various places of the database according to the data loader configuration. However they remain linked to the product reference. All ingested data files are referenced in a dedicated collection. Datasets contained in products are located in various places of the database according to the data loader configuration. However they remain linked to the product reference.
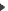 All products are linked to their inner datasets All products are linked to their inner datasets
Datasets own links pointing back to the datafile they come from.
The Saada dataloader can load only one extension (dataset) at the time. A data filecontaining for instance 2 images and one spectra must be processed 3 times to be totally ingested.
At loading time, the dataloader checks if the requested extension is present in the product. If it is, the dataloader verifies if the file has already been processed or not(use of a MD5 signature). If the file hasn’t been processed before a new record is created. The extension is then loaded while links are set up with the root product.
All product records have attributes (SQL columns) computed by Saada in addition to their specific attributes. One specific attribute is created for each header keyword excepted HISTORY and CONTINUE.
Products having the same set of specific attributes are grouped in the same same class. This class is automatically created by Saada. Its name is derivated from the name of the first file of the class. Products of a given class can be selected by SaadaQL with constraints on any specific attributes.
Common attributes computed by Saada can be used to select products with consideration for their class. The table below lists these common attributess
| Attribute | Purpose |
|---|
| oidsaada |
Unique identifier computed by Saada |
| md5key |
Numerical signature of the product content |
| filename |
Product filename |
| format |
Product file format |
| load_date |
Date of the product loading |
| permission |
Not used yet |
| owner |
Not used yet |
last update 2007-03-23
|

